
IA-32(X86-32)
–IA-32 %eax, %ecx, %edx, %ebx, %esi, %edi, %esp, %ebp
–X86-64 %rax, %rcx, %rdx, %rbx, %rsi, %rdi, %rsp, %rbp
–MIPS32 $0… $31 $t0
通用寄存器
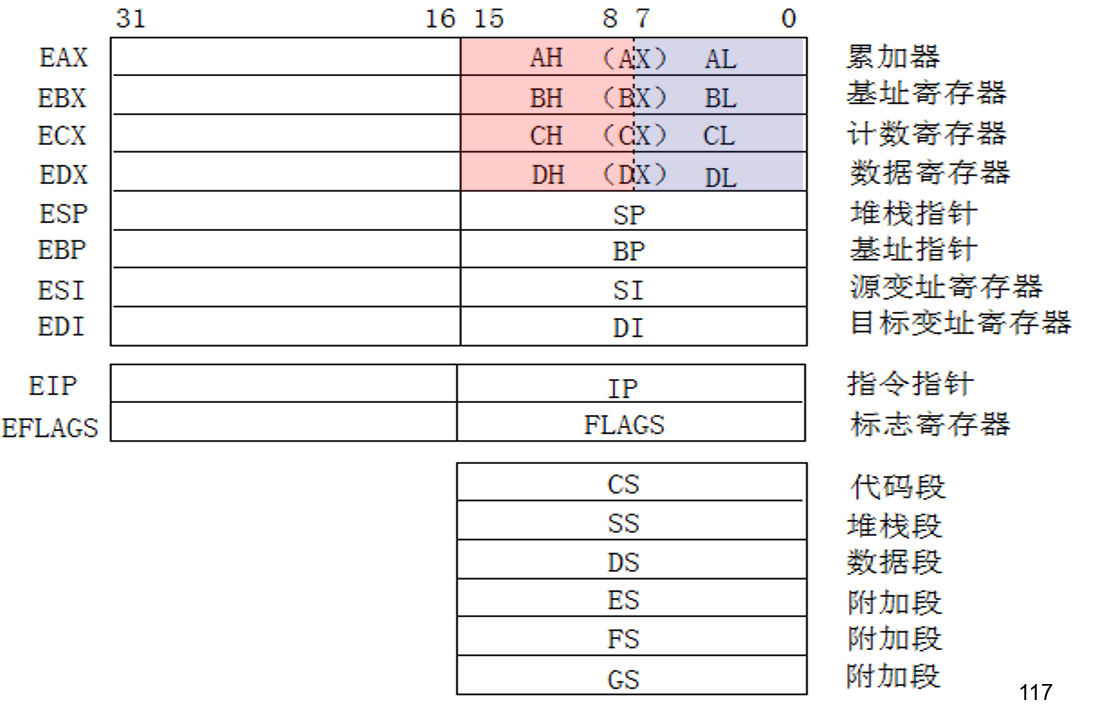
%eax:累加寄存器,用于算术运算和函数返回值result。 acc / res
%ecx:计数寄存器,用于循环计数i 和字符串操作。 count
%edx:数据寄存器,用于 I/O 操作和乘法/除法运算。 data/ temp
%esi:源索引寄存器,用于字符串操作。 src index
%edi:目标索引寄存器,用于字符串操作。dst index
%ebx:基址寄存器,用于基址寻址。 base
%esp:栈指针寄存器,用于栈操作。 stack pointer
%ebp:基址指针寄存器,用于访问函数参数和局部变量。 base pointer
-
%eax(累加寄存器,Accumulator Register)
-
用途:主要用于算术运算和函数返回值。
-
示例:
movl %ebx, %eax ; 将 %ebx 的值复制到 %eax add $1, %eax ; 将立即数 1 加到 %eax 中
-
-
%ecx(计数寄存器,Count Register)
-
用途:主要用于循环计数和字符串操作。
-
示例:
mov $10, %ecx ; 将立即数 10 加到 %ecx 中 loop label ; 如果 %ecx 不为零,跳转到 label 并将 %ecx 减 1
-
-
%edx(数据寄存器,Data Register)
-
用途:主要用于 I/O 操作和乘法/除法运算。
-
示例:
mov %eax, %edx ; 将 %eax 的值复制到 %edx
-
-
%ebx(基址寄存器,Base Register)
-
用途:主要用于基址寻址。
-
示例:
mov %ebx, %eax ; 将 %ebx 的值复制到 %eax mov (%ebx), %eax ; 将 %ebx 指向的内存地址的值加载到 %eax
-
-
%esi(源索引寄存器,Source Index Register)
-
用途:主要用于字符串操作,作为源地址。
-
示例:
mov %esi, %eax ; 将 %esi 的值复制到 %eax
-
-
%edi(目标索引寄存器,Destination Index Register)
-
用途:主要用于字符串操作,作为目标地址。
-
示例:
mov %edi, %eax ; 将 %edi 的值复制到 %eax
-
-
%esp(栈指针寄存器,Stack Pointer Register)
-
用途:指向当前栈顶,用于栈操作。
-
示例:
push %eax ; 将 %eax 的值压入栈中,%esp 减少 4 pop %eax ; 从栈中弹出值到 %eax,%esp 增加 4
-
-
%ebp(基址指针寄存器,Base Pointer Register)
-
用途:指向当前栈帧的基址,用于访问函数参数和局部变量。
-
示例:
movl %esp, %ebp ; 将 %esp 的值复制到 %ebp
-

x86-32标志寄存器(EFLAGS)介绍
重要标志位
- CF (Carry Flag) - 进位标志
- 无符号运算时的进位/借位
- 最高位产生进位时置1
- ZF (Zero Flag) - 零标志
- 运算结果为0时置1
- 常用于比较操作
- SF (Sign Flag) - 符号标志
- 运算结果为负时置1
- 等于结果的最高位
- OF (Overflow Flag) - 溢出标志
- 有符号运算时的溢出
- 结果超出表示范围时置1
- PF (Parity Flag) - 奇偶标志
- 结果中1的个数为偶数时置1
- AF (Auxiliary Flag) - 辅助进位标志
- 低4位向高4位进位时置1
- BCD运算中使用
常见使用场景
# 条件跳转指令使用标志位
je label # ZF=1 时跳转
jne label # ZF=0 时跳转
jg label # 有符号大于时跳转 (SF=OF 且 ZF=0)
jl label # 有符号小于时跳转 (SF≠OF)
ja label # 无符号大于时跳转 (CF=0 且 ZF=0)
jb label # 无符号小于时跳转 (CF=1)
标志位对于条件判断和程序流程控制至关重要。
高级语言转换成机械代码的过程
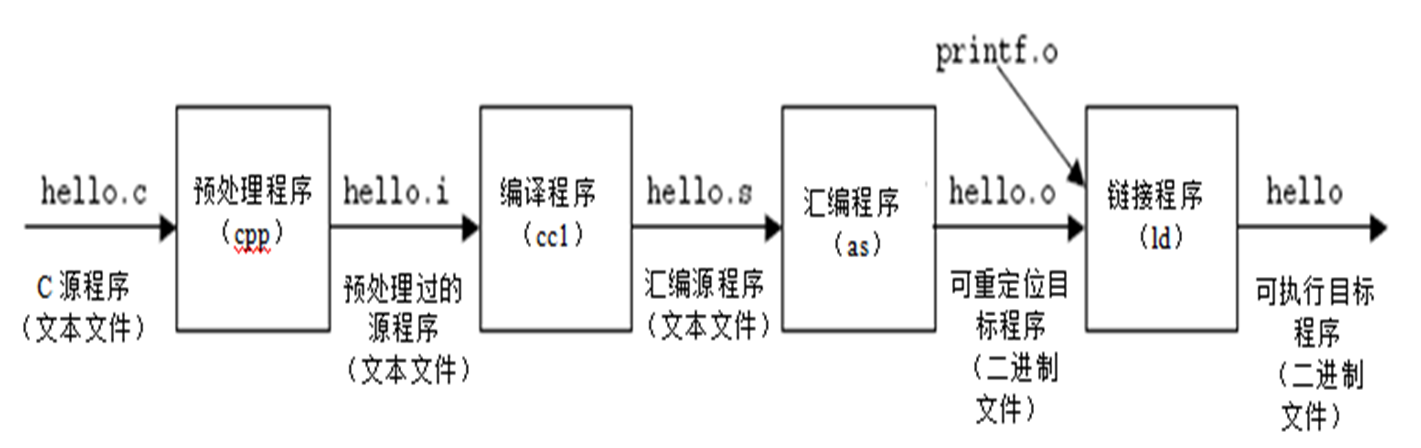
- 预处理:在高级语言源程序.c中插入include和define宏 .i
- 编译:预处理后的源程序文件.i 编译成相应的汇编程序 .s
- 汇编:由汇编程序将汇编语言源程序转换为.o
- 链接:由链接器将.o 和库例程链接起来生成exe
指令:
AT&T格式x86-32基本汇编指令概览
语法特点:
- 源操作数在左,目标操作数在右
- 寄存器名前需要加%
- 立即数前需要加$
- 操作数大小使用后缀:b(byte), w(word), l(long)
# 数据传送指令
movl $123, %eax # 立即数 -> 寄存器
movl %eax, %ebx # 寄存器 -> 寄存器
movl (%eax), %ebx # 内存 -> 寄存器
movl %eax, (%ebx) # 寄存器 -> 内存
movsbl %al, 0xf0c(%esp) #sign
带符号扩展(sign extend)
将8位的al寄存器值扩展为32位
存储到esp+0xf0c的内存位置
movzbl %al, 0xf0c(%esp) #zero
零扩展(zero extend)
将8位的al寄存器值扩展为32位
高位补0
存储到esp+0xf0c的内存位置
movw $0xfffe, 0xc0c(%esp,%eax,2) #word
复杂的地址计算:esp + 0xc0c + eax*2
将16位立即数0xfffe
存储到计算出的内存地址
# 算术运算指令
addl %eax, %ebx # ebx = ebx + eax
subl %eax, %ebx # ebx = ebx - eax
imull %eax, %ebx # ebx = ebx * eax
divl %ebx # edx:eax / ebx
# 栈操作指令
pushl %eax # 压栈
popl %eax # 出栈
# 比较和跳转
cmpl %eax, %ebx # 比较
je label # 相等则跳转eab == eax
jmp label # 无条件跳转
testl %eax, %eax # 检查%eax是否为0
je label # 如果为0则跳转 if eax & eax ==0 jmp
testl $0x1, %eax # 测试最低位
jnz odd_label # 如果最低位为1跳转(奇数) if eax & 0x1 !=0 jmp
# 函数调用
call function # 调用函数
ret # 函数返回
# 其他常用指令
andl %eax, %ebx # 按位与
orl %eax, %ebx # 按位或
xorl %eax, %eax # 异或(常用于清零)
leal source, destination # AT&T格式
特点
- 不访问内存,只计算地址
- 常用于:
- 快速计算
- 指针操作
- 数组索引
# 基本使用
leal (%eax), %ebx # ebx = eax
leal 4(%eax), %ebx # ebx = eax + 4
leal (%eax,%ebx), %ecx # ecx = eax + ebx
leal (%eax,%ebx,4), %ecx # ecx = eax + ebx*4
与mov的区别
movl (%eax), %ebx:从eax指向的内存读取值到ebxleal (%eax), %ebx:将eax的值(地址)复制到ebx
系统调用指令
-
INT:软件中断,用于系统调用。
int 0x80 ; 调用 Linux 系统调用
多级调用
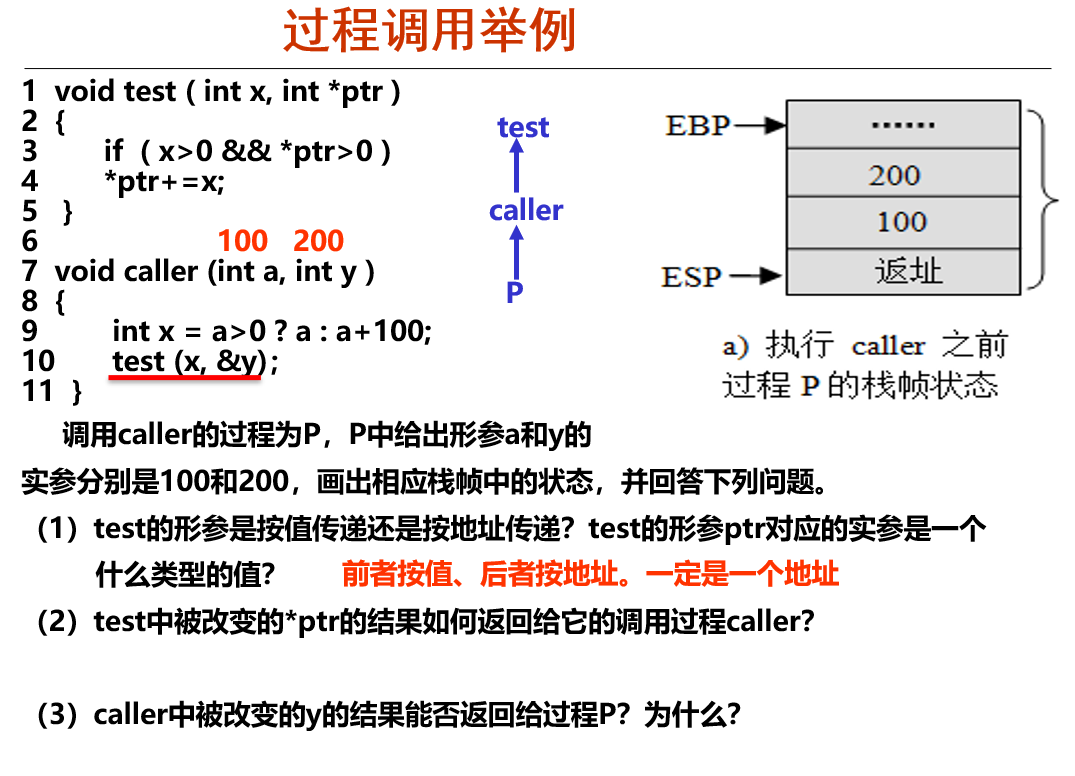
- 从右到左读取参数
- esp指向栈顶(返回地址),而不是esp指向了返回地址
- 进入函数前,会先把参数压入栈中,再保存ebp
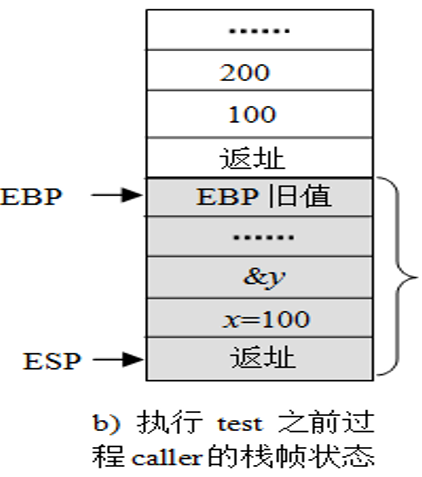
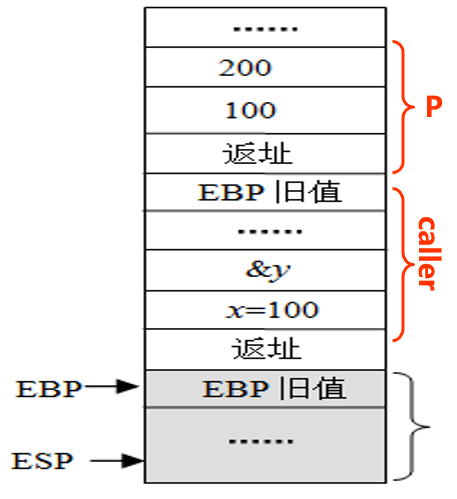
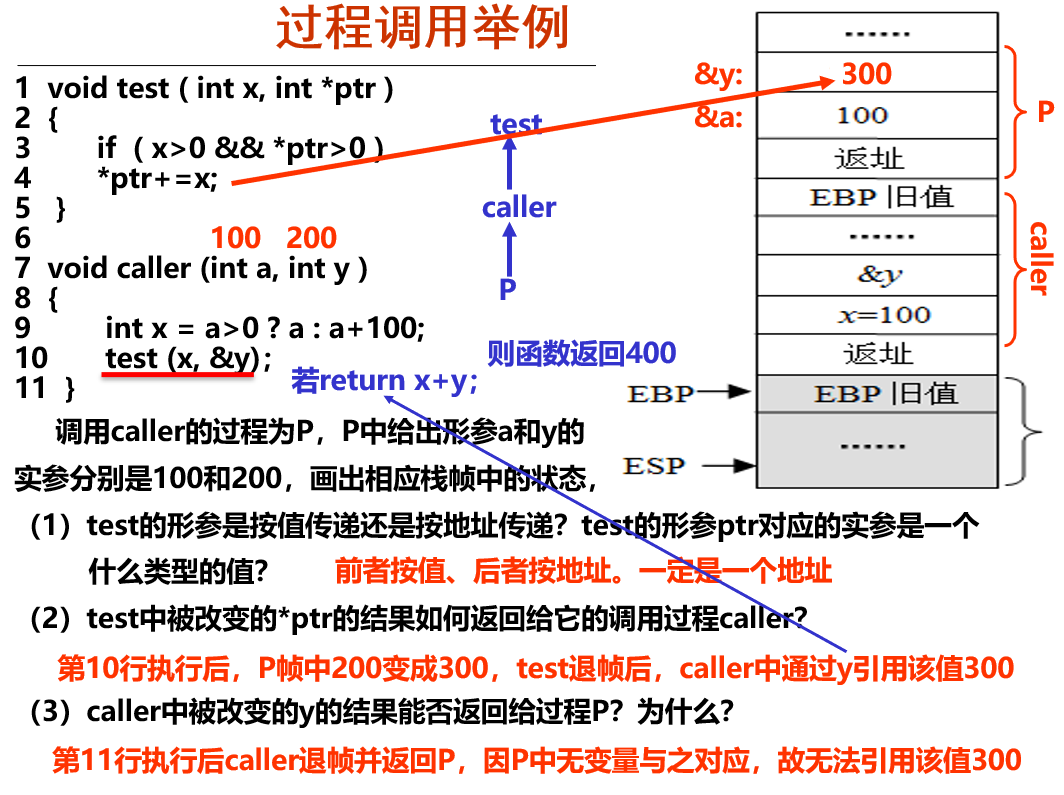
- caller结束后,返回P。变量a y作为临时变量被销毁,P中没有变量接收y,故无法返回y
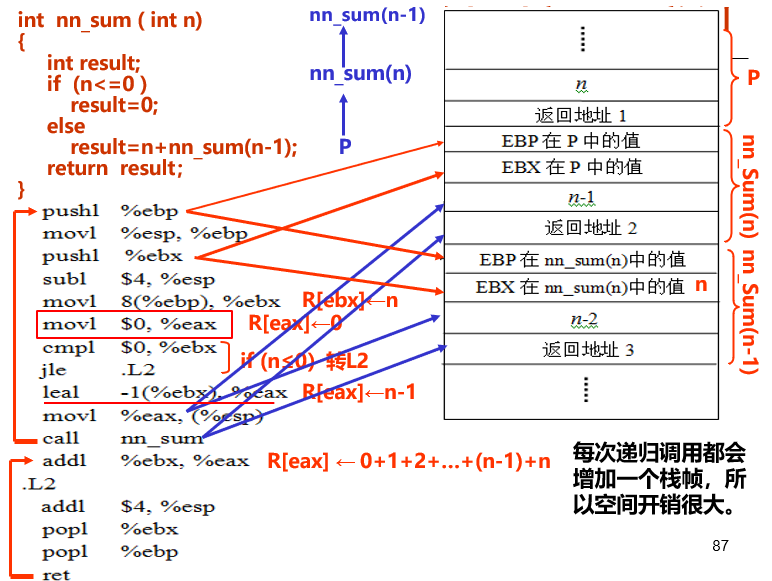
递归调用
2. 常见助记符规则
mov - move (移动数据)
add - add (加法)
sub - subtract (减法)
mul - multiply (乘法)
div - divide (除法)
push - push (压栈)
pop - pop (出栈)
3. 后缀规则
l - long (32位)
w - word (16位)
b - byte (8位)
例如:
movl - 移动32位数据
movw - 移动16位数据
movb - 移动8位数据
4. 指令类别标识
- 算术运算:add, sub, mul, div
- 数据传送:mov, push, pop
- 控制转移:jmp, call, ret
- 比较指令:cmp, test
- 位操作:and, or, xor, not
a+b
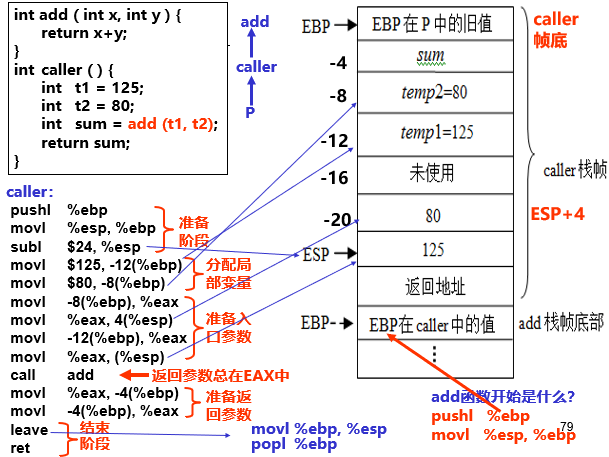
movl 表示mov一个long32bit

pushl %ebp #固定旧的ebp
movl %esp, %ebp #esp 指向栈顶,ebp指向
subl $16, %esp #$16立即数,esp撤出16B,4long,esp向下移动四个位置给临时变量
movl 12(%ebp), %eax #16~12 ->eax, 基址加偏移量(间接寻址)取出内存内容放到寄存器eax
movl 8(%ebp), %edx #11~8 ->edx
addl %edx,%eax #eax+=edx
movl %eax, -4(%ebp) #ans -> M[R[%ebp]-4]
movl -4(%ebp), %eax #保存寄存器eax的值(后续返回),同时写入内存
leave
ret
+-----------------+# x86规定从参数右向左入栈
| 参数 2 |
+-----------------+
| 参数 1 |
+-----------------+
| 返回地址 |
+-----------------+
| 调用者的 %ebp | <- %ebp (movl %esp, %ebp) ebp指向原来的栈顶
+-----------------+
#自上而下看,倒栈,上面是高地址,下面是低地址
main(){
func();
}
func(long a, long b){
return a+b; #隐式生成了一个临时变量x x=a+b
}
#移动esp后
高地址
| 参数2 | +12(%ebp)
| 参数1 | +8(%ebp)
| 返回地址 | +4(%ebp)
| 旧的%ebp | (%ebp)
| 局部变量 | -4(%ebp) #临时变量x
| ... |
| 未使用空间 |
低地址 | (%esp)
返回地址(Return Address)和旧的ebp在栈中的区别:
区别分析
- 返回地址(Return Address)
- 记录函数调用完成后应该返回到的程序位置
- 由
call指令自动压入栈中 - 位于
ebp+4的位置 - 在函数返回时由
ret指令使用来恢复程序执行流
- 旧的ebp
- 保存调用者函数的栈帧基址
- 由
pushl %ebp指令手动保存 - 位于
ebp指向的位置 - 用于在函数结束时恢复调用者的栈帧
栈帧示意图
高地址
| 参数2 | ebp+12
| 参数1 | ebp+8
| 返回地址 | ebp+4 (call指令压入)
| 旧的ebp | ebp (push ebp压入)
| 局部变量 | ebp-4
低地址
movl %esp, %ebp
- 返回地址:确保程序能够正确返回到调用点继续执行
- 旧的ebp:维护栈帧链表,使得函数调用结束后能够正确恢复调用者的栈帧结构
这两个值对于函数调用的正确执行都是必不可少的。
让我解释 movl %esp, %ebp 这条指令在函数调用中的作用:
作用
这条指令是建立新的栈帧(stack frame)的关键步骤。
执行步骤
- 函数调用开始时,通常先执行:
pushl %ebp # 保存旧的栈帧基址
movl %esp, %ebp # 建立新的栈帧基址
为什么要这样做?
- 栈帧建立
- esp总是指向栈顶
- 调用新函数时需要新的栈帧基址
- 将esp的值复制给ebp,使ebp指向新栈帧的底部
- 局部变量访问
- ebp作为固定参考点
- 通过ebp可以稳定访问:
- 局部变量 (负偏移)
- 参数 (正偏移)
- 栈帧示意图
调用前: 调用后:
高地址 高地址
esp -> |旧ebp| ebp -> |旧ebp|
低地址 esp -> | |
低地址
这样设计让每个函数都有自己独立的栈帧,便于管理局部变量和参数。
lea指令计算原理解释
- lea的本质功能
- 不是真正的地址计算
- 实际是利用地址计算单元(AGU)进行整数计算
- AGU本来用于计算内存访问地址
- 为什么可以改变值
leal (%edx, %eax), %eax # 看似在计算地址
# 实际效果
# %eax = %edx + %eax # 但实际是在做加法运算
- 设计优势
- 利用地址计算单元完成算术运算
- 避免使用ALU(算术逻辑单元)
- 减少指令延迟
- 提高执行效率
- 实际应用
# 计算5倍
leal (%eax, %eax, 4), %eax # eax = eax + eax*4
# 计算数组索引
leal (%ebx, %ecx, 4), %edx # edx = ebx + ecx*4
lea指令实际上是借用了地址计算硬件来完成算术运算的一种优化技巧。
为什么需要写入内存,而不直接返回
movl %eax, -4(%ebp) #ans -> M[R[%ebp]-4]
movl -4(%ebp), %eax #保存寄存器eax的值(后续返回),同时写入内存
这两条指令看似冗余,但有其存在的必要性:
- 编译器优化策略
- 保证函数调用约定
- 维护栈帧的完整性
- 确保数据一致性
- 实际作用
movl %eax, -4(%ebp) # 将结果存入栈帧的局部变量区
movl -4(%ebp), %eax # 再次加载到eax用于返回
- 为什么不直接返回
- 如果函数后续还有其他操作,可能会修改eax
- 其他函数调用可能改变eax的值
- 局部变量作为安全的临时存储
- 便于调试(可以在内存中查看中间结果)
- 优化相关
- 在开启优化的情况下,编译器可能会消除这种冗余操作
- 但在调试版本中保留这些操作更安全
这是一种防御性编程的实践,虽然看似冗余但增加了代码的可靠性。
Switch

- 如果a-10 大于7 ,返回a; ja : jump if above unsigned cmp
- 否则,跳转至 4*eax +.L8 ,4字节对齐eax 为偏移量,.L8为基址
寻址方式
1. 立即数(Immediate)
立即数是直接在指令中指定的常量值,前面加上$符号。
movl $10, %eax ; 将立即数10加载到寄存器%eax
2. 寄存器(Register)
寄存器寻址是直接使用寄存器的值。
movl %eax, %ebx ; 将寄存器%eax的值复制到寄存器%ebx
3. 直接内存(Direct Memory)
直接内存寻址是使用内存地址来访问数据。
movl var, %eax ; 将内存地址var处的值加载到寄存器%eax
4. 间接内存(Indirect Memory)
间接内存寻址是通过寄存器的值作为内存地址来访问数据。
movl (%eax), %ebx ; 将寄存器%eax指向的内存地址处的值加载到寄存器%ebx
5. 基址加偏移量(Base + Offset)
基址加偏移量寻址是使用寄存器的值加上一个常量偏移量作为内存地址。
movl 4(%eax), %ebx ; 将寄存器%eax加上偏移量4处的内存地址的值加载到寄存器%ebx
6. 基址加变址(Base + Index)
基址加变址寻址是使用两个寄存器的值相加作为内存地址。
movl (%eax,%ebx), %ecx ; 将寄存器%eax和%ebx的值相加作为内存地址处的值加载到寄存器%ecx
7. 基址加变址加偏移量(Base + Index + Offset)
基址加变址加偏移量寻址是使用两个寄存器的值相加再加上一个常量偏移量作为内存地址。
movl 4(%eax,%ebx), %ecx ; 将寄存器%eax和%ebx的值相加再加上偏移量4处的内存地址的值加载到寄存器%ecx
8. 基址加变址乘比例因子(Base + Index * Scale)
基址加变址乘比例因子寻址是使用一个寄存器的值加上另一个寄存器的值乘以比例因子作为内存地址。
movl (%eax,%ebx,4), %ecx ; 将寄存器%eax的值加上寄存器%ebx的值乘以4作为内存地址处的值加载到寄存器%ecx
9. 基址加变址乘比例因子加偏移量(Base + Index * Scale + Offset)
基址加变址乘比例因子加偏移量寻址是使用一个寄存器的值加上另一个寄存器的值乘以比例因子再加上一个常量偏移量作为内存地址。
movl 8(%eax,%ebx,4), %ecx ; 将寄存器%eax的值加上寄存器%ebx的值乘以4再加上偏移量8处的内存地址的值加载到寄存器%ecx
示例总结
movl $10, %eax ; 立即数
movl %eax, %ebx ; 寄存器
movl var, %eax ; 直接内存
movl (%eax), %ebx ; 间接内存
movl 4(%eax), %ebx ; 基址加偏移量
movl (%eax,%ebx), %ecx ; 基址加变址
movl 4(%eax,%ebx), %ecx ; 基址加变址加偏移量
movl (%eax,%ebx,4), %ecx ; 基址加变址乘比例因子
movl 8(%eax,%ebx,4), %ecx ; 基址加变址乘比例因子加偏移量
movl (%eax,%ebx), %ecx ;ecx = *(eax+ebx) ,访存(eax存的内容加上ebx存的内容作为基地址,偏移量0)
leal (%eax,%ebx), %ecx ;ecx = eax + ebx , 不访存,通过特别的方法完成将eax的内容加ebx的内容后移动到ecx
数组计算地址
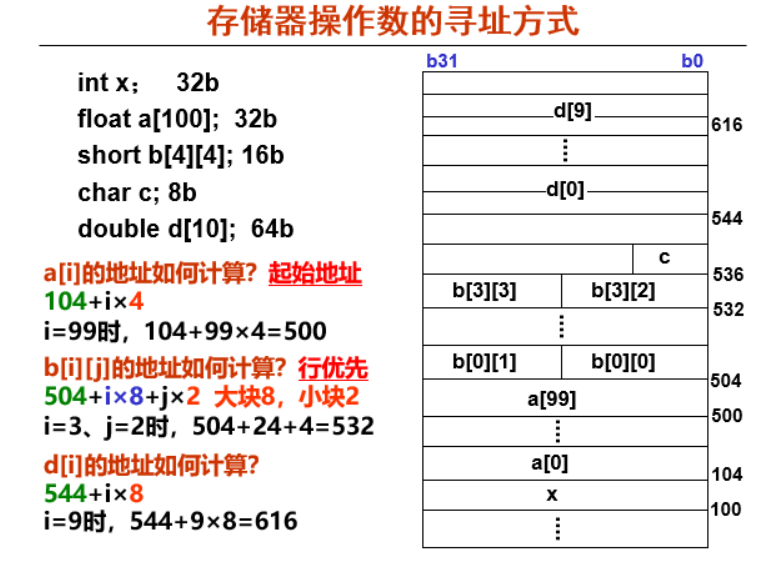

内存对齐
Q:为什么c独占64位?
内存对齐机制性能考虑CPU读取内存时是按"字"访问, 32位系统默认按4字节对齐, 64位系统默认按8字节对齐,实际情况根据不同数据的大小来对齐(向“上”对齐)//x86-64
struct Example {
char c; // 1字节
// 7字节padding
double d; // 8字节
};//sizeof(struct Example): 16B
struct Example {
char c;//1B
//3B padding
int d;//4B
};//sizeof(struct Example): 8B
- padding取决于后面成员的对齐要求
- double要求8字节对齐
- int只要求4字节对齐
- 所以padding长度不同

- edx 默认存放了buf[0]的地址,作为基址,或者用buf 指针头作为基址
初始化

movl $10 , -8(%ebp) ; buf[0] = 10
movl $20 , -4(%ebp) ; buf[1] = 20
leal -8(%ebp), %edx
数组与指针
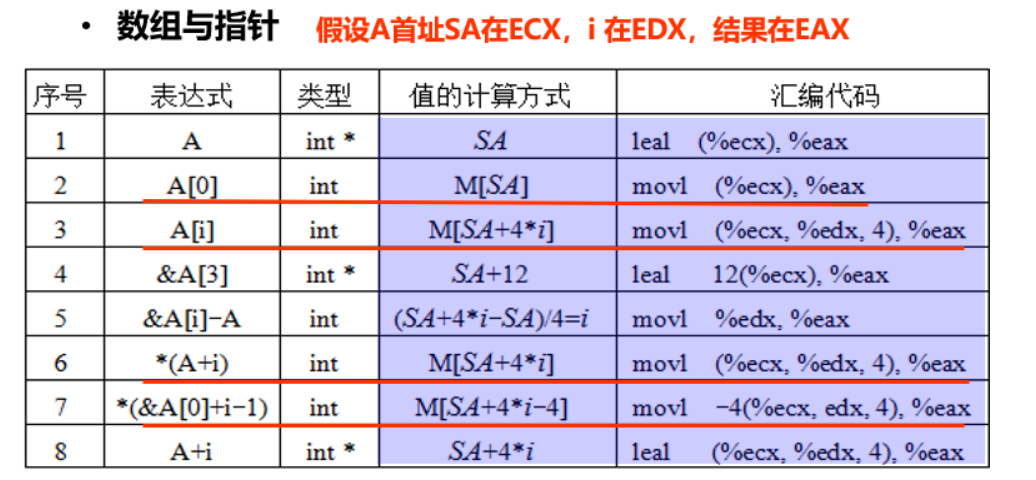
*(&A[0]+i-1)==>A[i-1]
M[SA+4*(i-1)]
-
指针(地址)间的运算,编译器会自动除以sizeof(int)
-
这种运算常用于计算数组元素之间的距离或索引差值
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
int *p;
int i =2;
p = a;
&a[1]-a = 1
&a[3]-&a[0] = 3
(int)&a[3]-(int)&a[0] = 12
*(p+1) = 2
*(a+1) = 2
*(&a[0]+i+1) = 4
p+=2 , *p = 3
p = a+1 , *p = 2

movl pn(,%ecx,4), %edx
addw (%edx), %ax
addl $2, pn(, %ecx, 4)
中的4是因为:
- 要访问的是指针数组pn
- 每个指针元素占4字节
- 与指针指向的short类型(2字节)无关
pn数组:
[ptr1][ptr2][ptr3][ptr4] # 每个指针4字节
↓ ↓ ↓ ↓
short short short short # 每个short 2字节
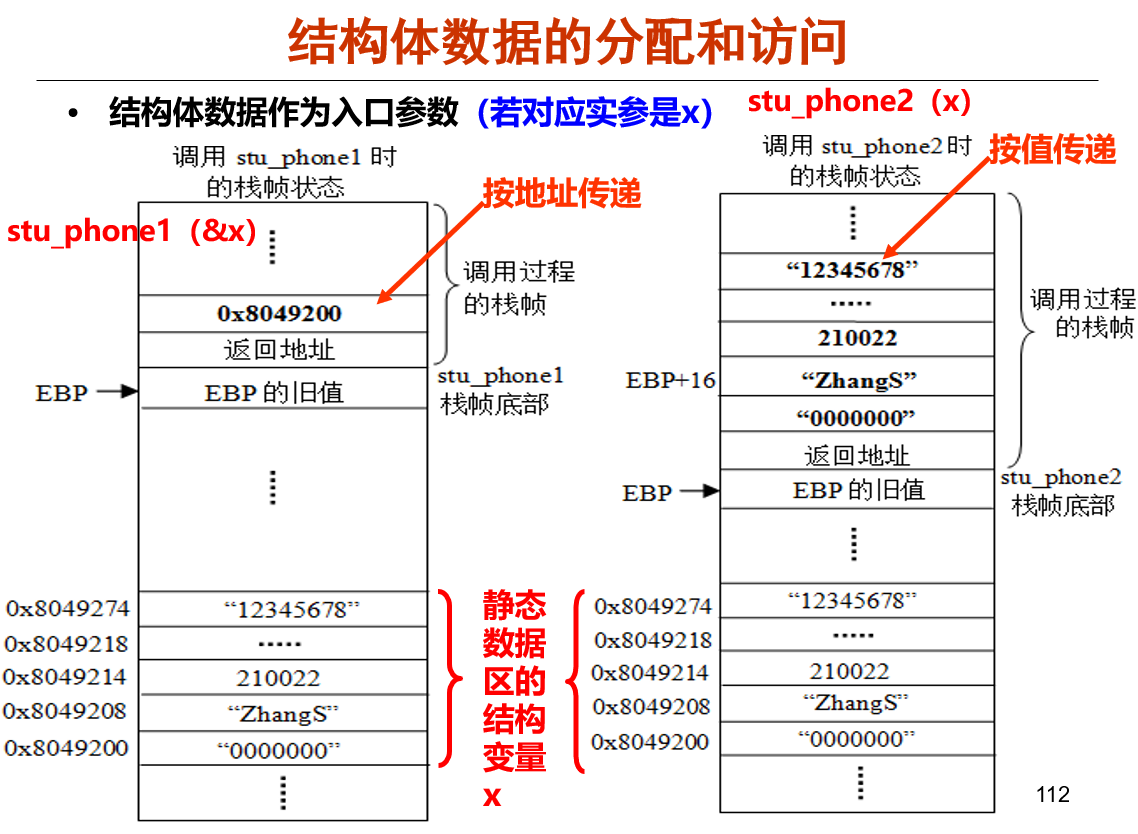
Struct

struct cont_info x={“0000000”, “ZhangS”, 210022, “273 long street, High Building #3015”, “12345678”};
Union

union Data {
int i; // 4字节
float f; // 4字节
char str[8]; // 8字节
}; // 整个union占8字节
//union 结构体所有成员共享一块内存,如果被初始化了,其他成员也使用这个值
enum Color {
RED, // 默认从0开始
GREEN, // 1
BLUE // 2
};//固定大小(通常4字节)

int main() {
union{
int i;
float f;
}un;
un.f = 10.0;
printf("0x%x\n", un.i);
}
//0x41200000 = | 0 |10000010|01000000000000000000000|
10.0 = 2^30 +2^24 + 2^21
IEEE 754单精度(32位)表示10
- 符号位(1位)
- 0 (正数)
- 指数位(8位)
- 10 = 1.25 × 2³
- 偏移量127
- 指数: 3 + 127 = 130 = 128 +2
- 二进制: 10000010
- 尾数位(23位)
- 1.25的二进制: 1.01
- 规格化后: 01000…0
+---+--------+----------------------+ | 0 |10000010|01000000000000000000000| +---+--------+----------------------+ 符号 指数 尾数
IEEE 754双精度(64位)表示
- 符号位(1位)
- 0 (正数)
- 指数位(11位)
- 偏移量1023
- 指数: 3 + 1023 = 1026 = 1024 +2
- 二进制: 10000000010
- 尾数位(52位)
- 同样是1.25的二进制表示
二进制: 0 10000000010 0100000000000000000000000000000000000000000000000000
大端/小端的区别
概念定义
- 大端方式: 高位字节存储在低地址
- 小端方式: 低位字节存储在低地址
示例说明
假设有一个32位整数: 0x12345678
1. 大端方式存储
低地址 高地址
+----+----+----+----+
| 12 | 34 | 56 | 78 |
+----+----+----+----+
2. 小端方式存储
低地址 高地址
+----+----+----+----+
| 78 | 56 | 34 | 12 |
+----+----+----+----+
代码示例
#include <stdio.h>
void check_endian() {
unsigned int x = 0x12345678;
unsigned char *p = (unsigned char *)&x;
if(*p == 0x78) {
printf("小端模式\n");
} else if(*p == 0x12) {
printf("大端模式\n");
}
// 打印每个字节
for(int i = 0; i < 4; i++) {
printf("%02x ", p[i]);
}
}
int main() {
check_endian();
return 0;
}
特点比较
- 小端模式
- x86 CPU使用小端模式
- 便于处理器进行加法运算
- Windows、Linux等主流操作系统采用
- 大端模式
- 符合人类读写习惯
- 网络字节序采用
- 部分RISC处理器采用
Volatile

注意事项
- 在x86-32系统中,int和long int大小相同
- 在x86-64系统中:
- int仍然是32位
- long int变成64位(8字节)
- 数据在内存中的排列x86-32
高地址 +--------------------------------+ | d[0] | 高4字节 | <--- a[3] | d[0] | 低4字节 | <--- a[2] +--------------------------------+ | a[1] | 4字节 (long int) | +--------------------------------+ | a[0] | 4字节 (long int) | +--------------------------------+ 低地址 - 访问分析
a[2] = 1073741824; // i = 2 时- 数组a只声明了2个元素(a[0]和a[1])
- a[2]实际上访问了a[1]之后的4字节内存
- 这4字节恰好是d[0]的低4字节位置
- 因为在小端系统中,数据是从低地址开始存储的
- 关键点
- 数组越界
- 内存连续性
- 小端存储方式
- volatile不能防止越界访问
逆向工程(汇编翻译成高级语言)

i = 0i != 32i++ , x <<=1result = (x & 0x1) | (result << 1),除了循环条件,一个分号只填一个语句
+-----------------+
| 参数 x | <---%ebp+8
+-----------------+
| 返回地址 |
+-----------------+
| 调用者的 %ebp |
+-----------------+
movl 8(%ebp), %ebx ; ebx = x
movl $0, %eax ; eax = 0, res =0
movl $0, %ecx ; ecx = 0, i=0
.L12:
leal (%eax,%eax), %edx ; edx = eax << 1
movl %ebx, %eax ; eax =ebx
andl $1, %eax ; eax = eax & 0x1
orl %edx, %eax ; eax =eax | edx
shrl %ebx ; ebx = ebx >> 1
addl $1, %ecx ;ecx ++ ,i++
cmpl $32, %ecx ; if ecx != 32 goto for so ecx = i
jne .L12
func(int x){
int res = 0;
int i;
for(i = 0; i!=32; i++, x > > =1){
edx = res << 1;
res = x;
res = res << 31;
res = res | edx;
//x = x >> 1;
}
}
res = ? | (res << 1);
==>
res = (x & 0x1) | (res << 1);
Comments